Exploring Regression Methods on Public Datasets
A semester capstone project to deepen understanding of upsides/downsides of different regression techniques. Methods were run 20 times each across 20 publicly available datasets and results were averaged.
My team was given the task of proposing an interesting capstone project, given what we learned in our Data Science and Analytics Course.
We landed on a benchmarking task in order to measure the “power” of various regression techniques on live, publicly available datasets. Click the link above to read the 1.5 page proposal.
Analyses Run
Multiple Linear Regression
K-Nearest Neighbors Regression
Ridge Regression
Lasso Regression
Bagging
Random Forest Regression
40 different datasets were gathered from a variety of sources, although the majority were pulled from Kaggle.com. The datasets were initially pulled if they seemed interesting, but ultimately the list was pared down to 20 datasets, eliminating ones that were not sufficiently large, diverse, or were not appropriate for regression analysis
Click the link above to see all ~40 datasets considered

Note: Click the “Analyses Run” link to view entire code set on Google Colab
Data Cleaning
Each dataset had unique cleaning requirements, but most followed similar procedures.
These included:
Changing data types with the .astype() function
Creating dummy variables for categorical predictors using pd.get_dummies()
Recoding boolean variables to 0 and 1 using np.where()
Re-coding ordinal string data into numerical format with OrdinalEncoder
Removing missing values using .dropna()
Results
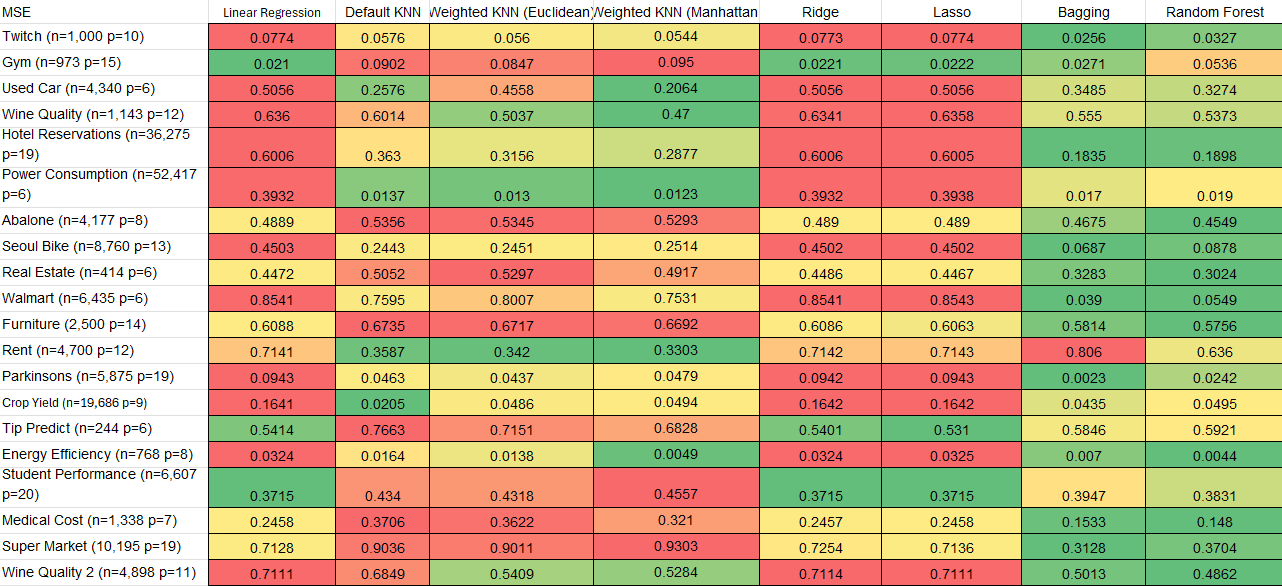
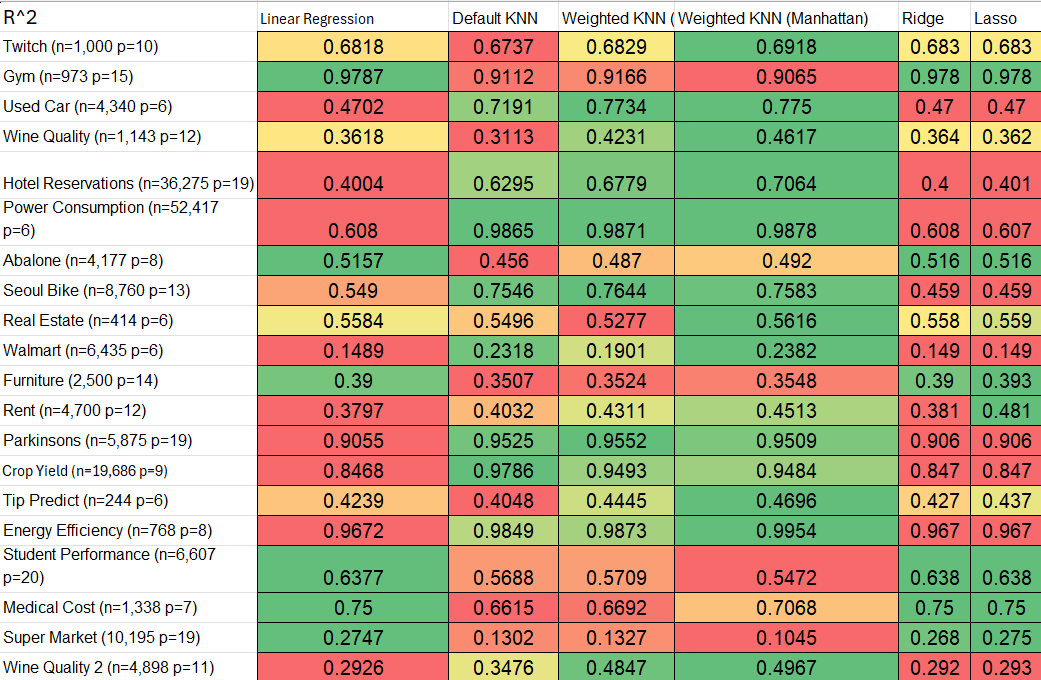
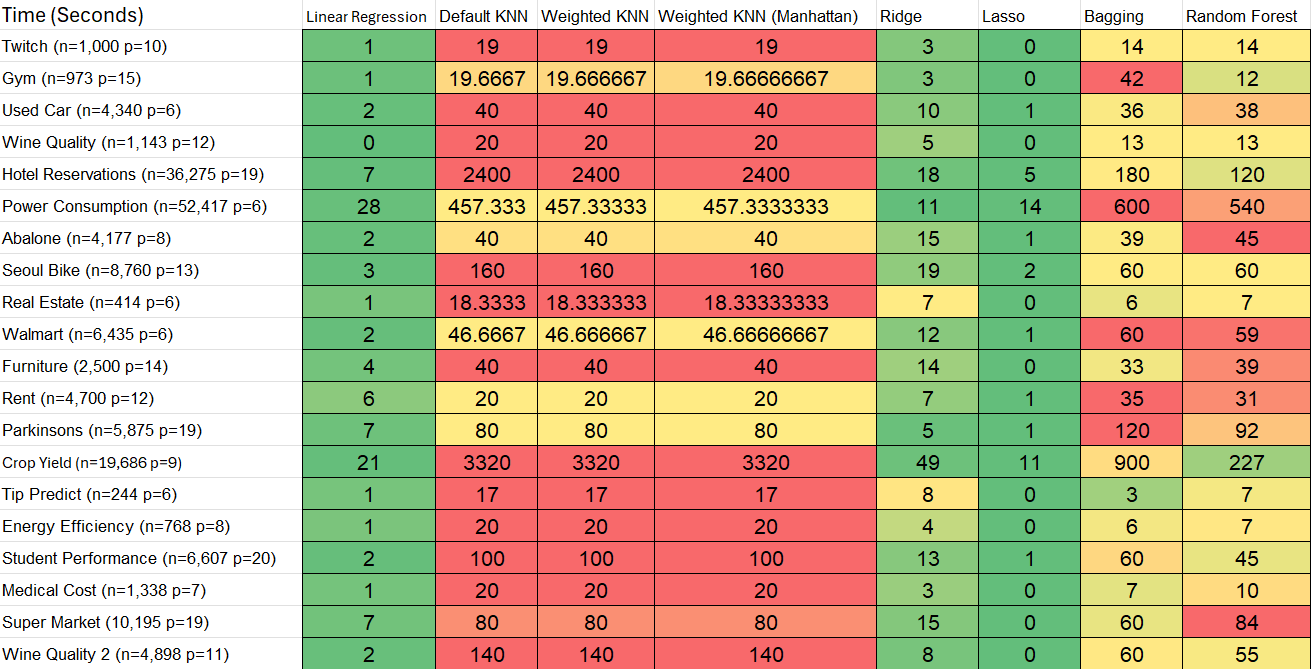
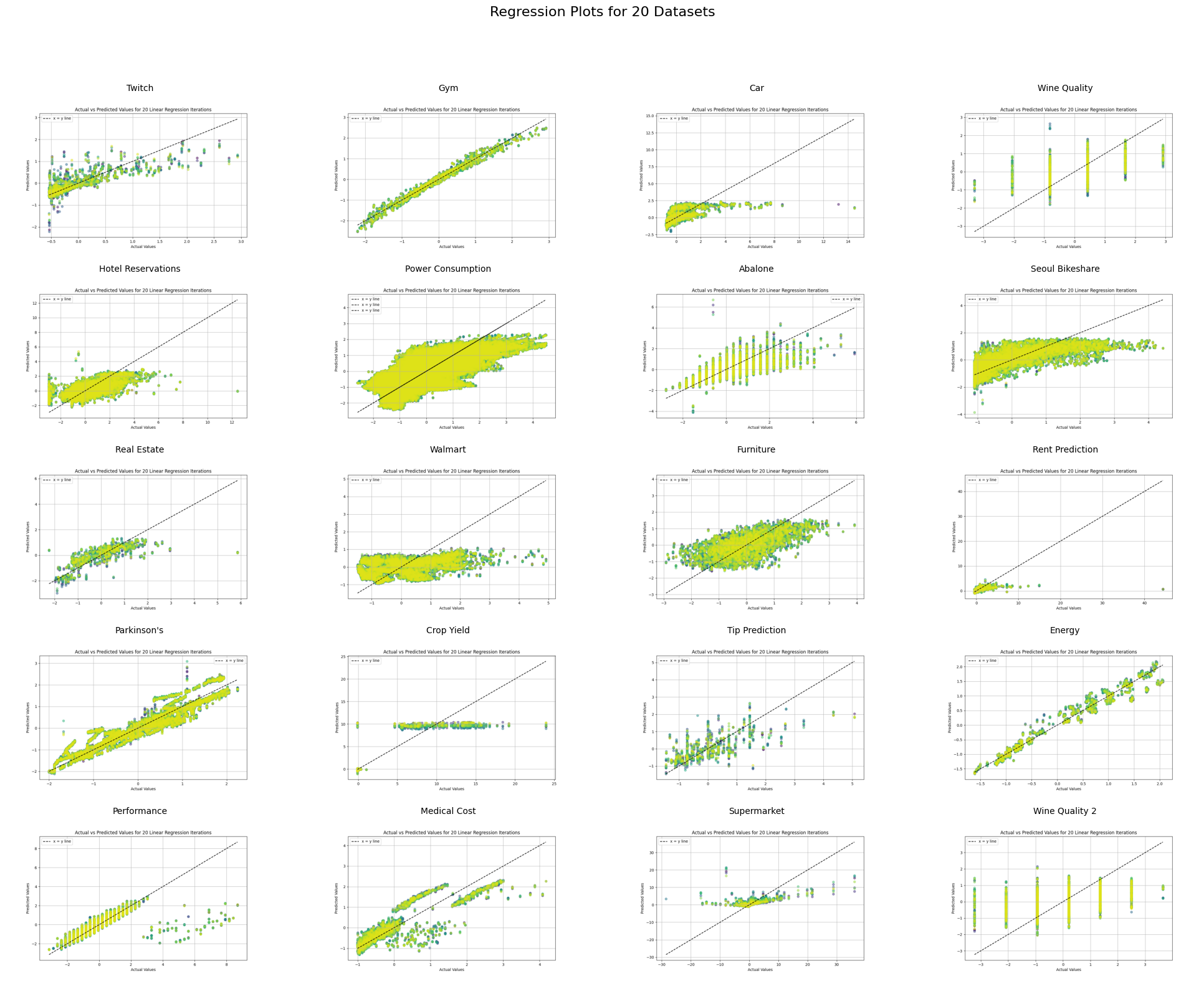
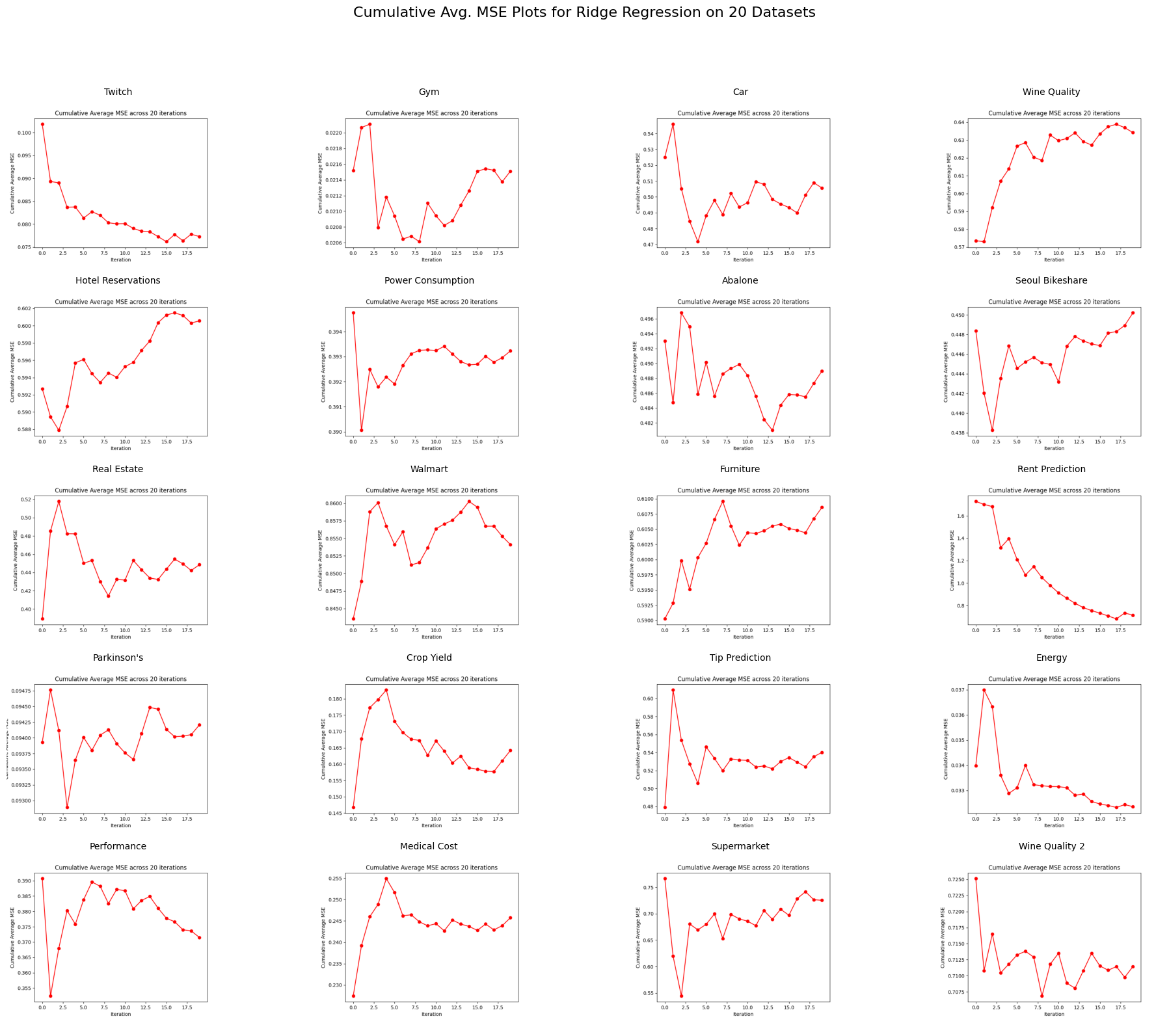
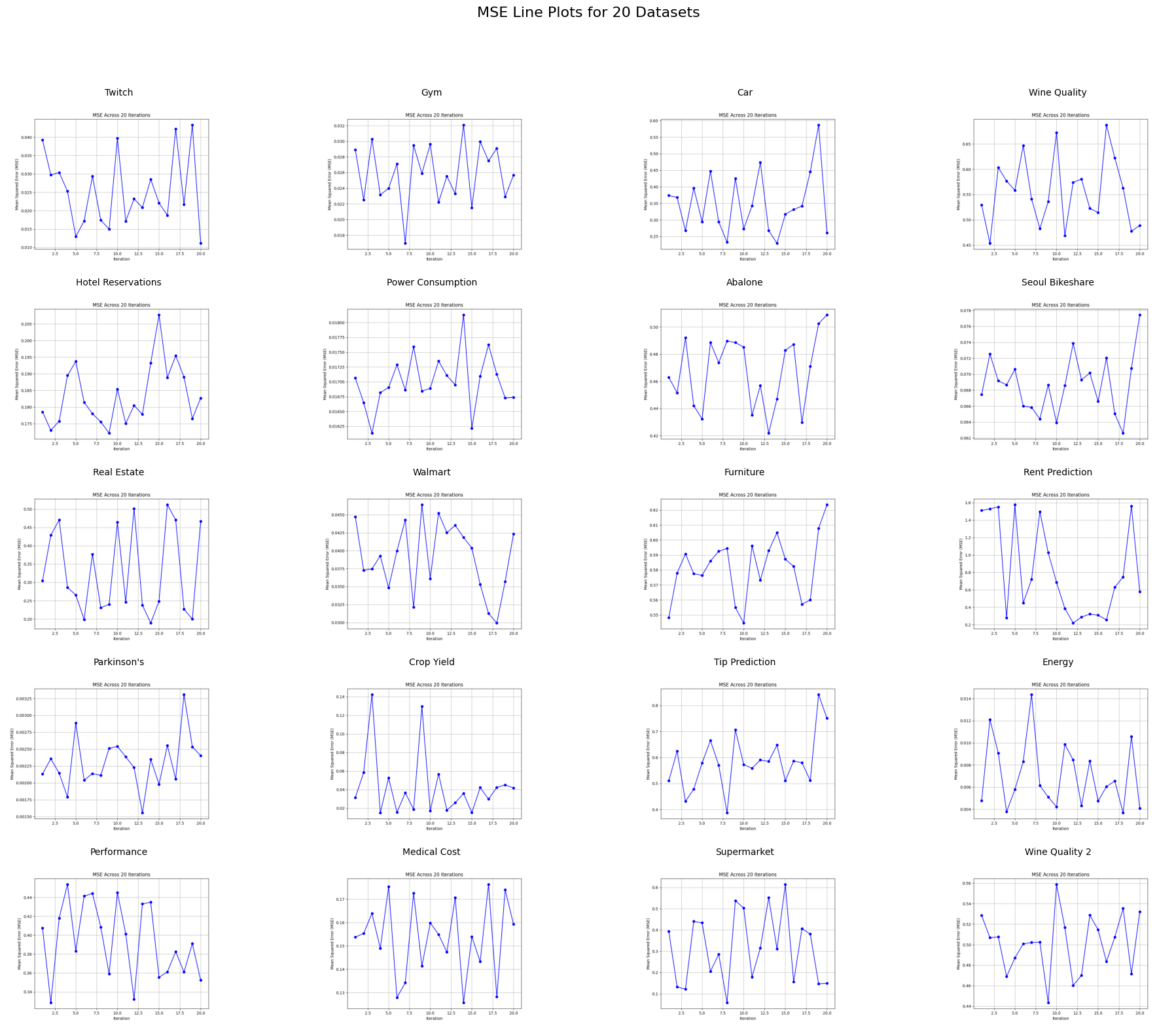
Note: Click the “Conclusions” link to view the report in its entirety
This was a great exercise to explore the application of several different machine learning algorithms, as well as to compare their relative strengths across different data sets and types.
Through the analysis of computation times, we observed significant variations in the efficiency of the algorithms. KNN and Bagging were notably slow, especially on larger datasets, whereas simpler models like Lasso exhibited faster performance without compromising too much on accuracy. This highlighted the trade-off between model complexity and computation time, emphasizing the importance of considering both factors in practical applications, especially with larger datasets. The performance metrics (MSE, MAE, etc) revealed that while KNN often outperformed Linear Regression in terms of accuracy, the Bagging function generally showed the best overall performance in most cases.
One of the key lessons learned was the importance of model optimization and data preprocessing. Some models, like KNN, performed poorly on large datasets due to inefficiencies in the code, highlighting the need for optimizing algorithms for speed. Additionally, we realized the importance of understanding the data characteristics before applying certain models. For example, datasets with noise or outliers caused instability in certain models, demonstrating the need for better data cleaning and preprocessing.